We introduce Enigmata, the first comprehensive suite tailored for improving LLMs with puzzle reasoning skills, which integrates seamlessly with reinforcement learning using verifiable rule-based rewards.
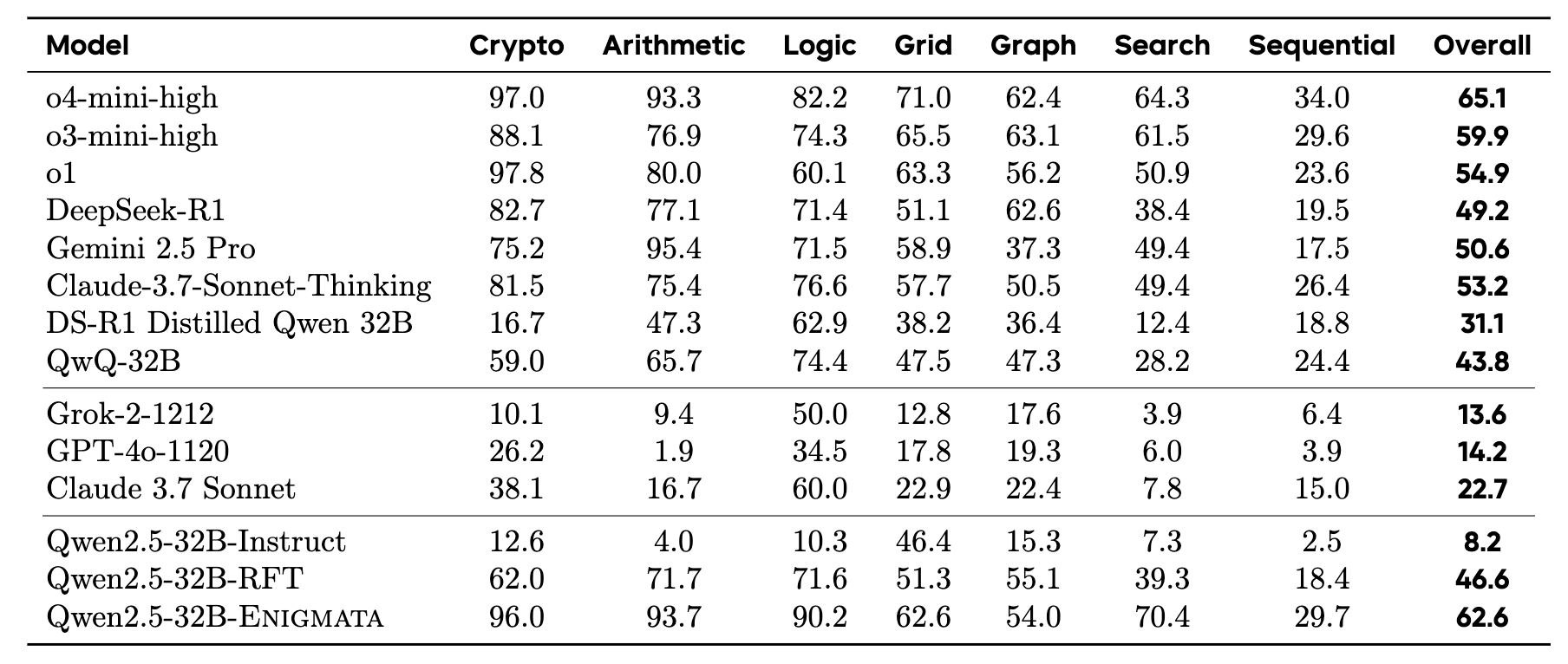
Enigmata-Data includes 36 tasks across 7 categories, each with: 1) a generator that produces unlimited examples with controllable difficulty, and 2) a rule-based verifier for automatic evaluation. This generator-verifier design supports scalable, multi-task RL training, fine-grained analysis, and seamless RLVR integration. We further propose Enigmata-Eval, a rigorous benchmark for assessing puzzle reasoning abilities and guiding research on generalizable reasoning models.
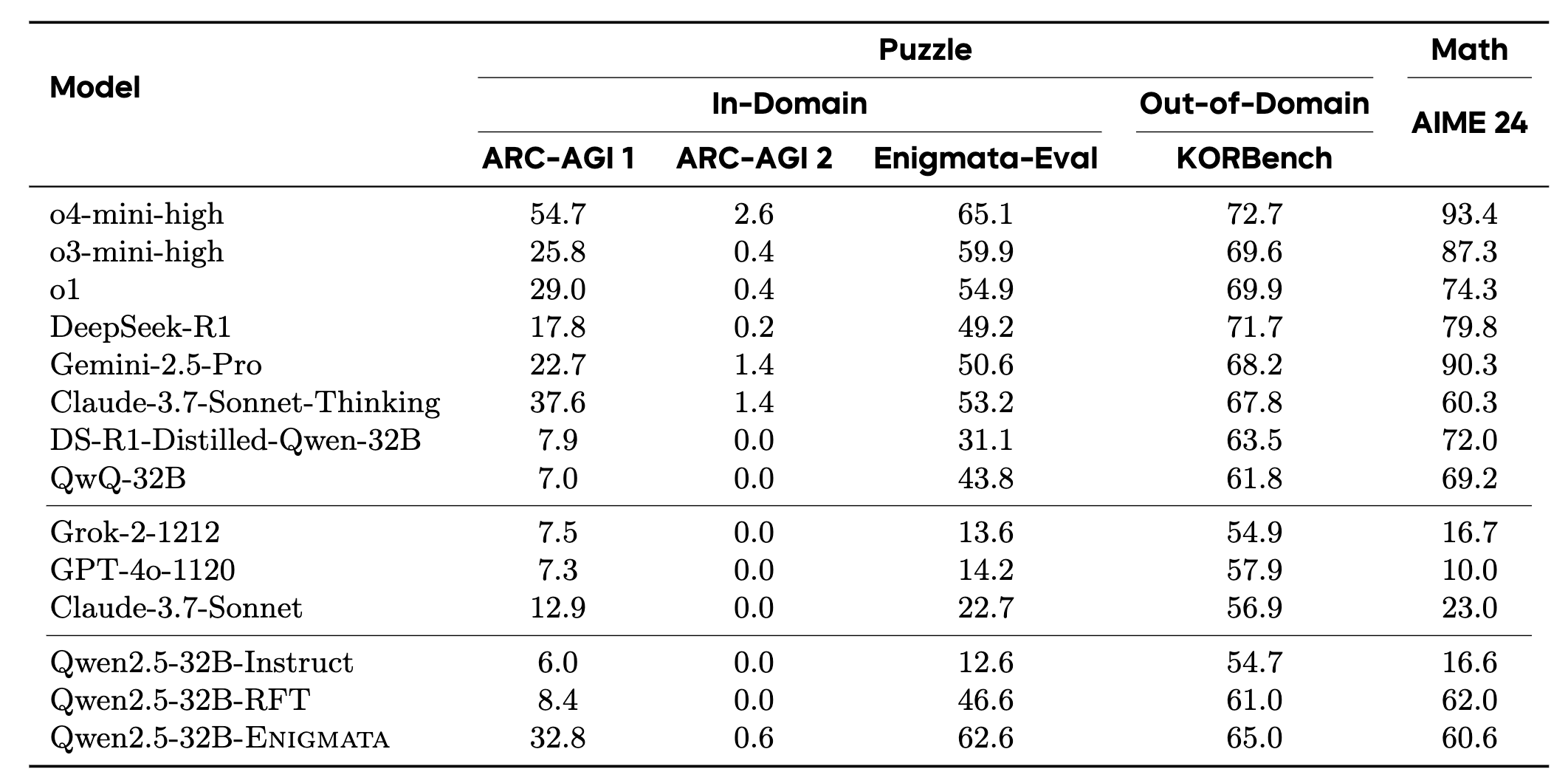
Qwen2.5-32B-Enigmata, trained with RLVR, consistently surpasses o3-mini-high and o1 on the puzzle reasoning benchmarks like Enigmata-Eval, ARC-AGI, and ARC-AGI 2. It also generalizes well to out-of-domain puzzle benchmarks and mathematical reasoning, with little multitasking trade-off.
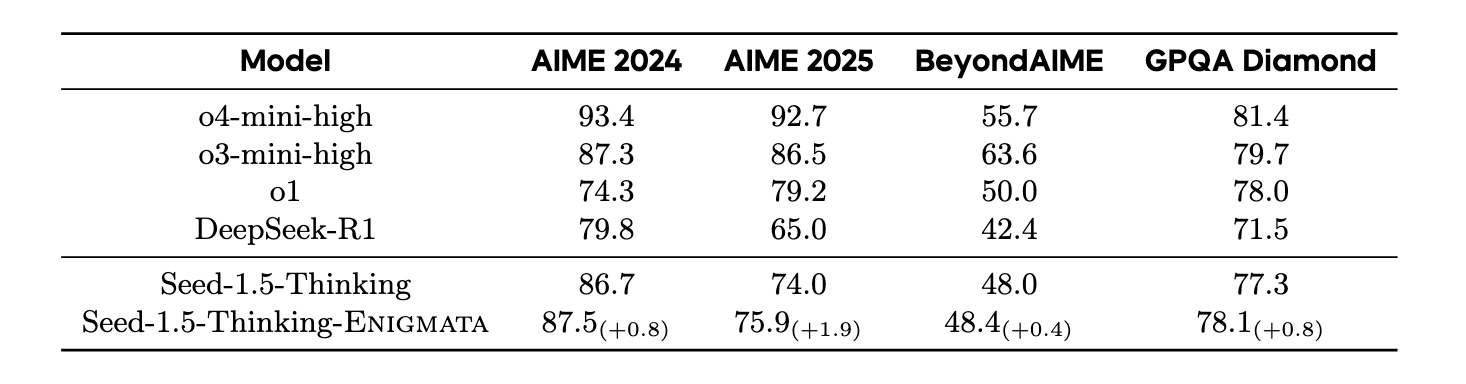
When trained on larger models like Seed1.5-Thinking (20B activated parameters and 200B total parameters), puzzle data from Enigmata further boosts SoTA performance on advanced math and STEM reasoning tasks such as AIME (2024-2025), BeyondAIME and GPQA (Diamond), showing nice generalization benefits of Enigmata.